
(Phần 1, Phần 2, Phần 3, Phần 4)
Nội dung
Chương 3: Device Driver Fundamentals in C
- 1. Hiểu về Memory Map
- 2. Planning the Driver Interfaces
- 3. Design by Contract
- 4. Assertion Fundamentals
- 5. Device Driver Models
- 6. Polling Versus Interrupt-Driven Drivers
- 7. Driver Component Definition
- 8. Naming Convention Recommendations
- 9. Object-Oriented Programming in C
- 10. Abstractions and Abstract Data Types (ADTs)
- 11. Encapsulation and Data Hiding
- 12. Callback Functions
- 13. Error Handling
- 14. Leverage Design Patterns
- 15. Expected Results and Recommendations
- 16. Going Further
9. Lập Trình Hướng Đối Tượng trong C
Các developer nên xem xét việc phát triển driver và application code của họ theo hướng đối tượng. Ngôn ngữ lập trình C không phải là ngôn ngữ lập trình hướng đối tượng (object-oriented programming). C là một ngôn ngữ lập trình thủ tục (procedural programming) trong đó trọng tâm chính là xác định một loạt các bước và thủ tục có cấu trúc tốt trong ngữ cảnh lập trình của nó để tạo ra một chương trình.7 Mặt khác, một ngôn ngữ lập trình hướng đối tượng là một ngôn ngữ lập trình tập trung về định nghĩa và các hoạt động được thực hiện trên dữ liệu.
Có một số đặc điểm khiến ngôn ngữ lập trình hướng đối tượng khác với ngôn ngữ thủ tục. Bao gồm:
- Abstraction (Sự trừu tượng)
- Encapsulation (Đóng gói)
- Objects (Đối tượng)
- Classes
- Inheritance (Kế thừa)
- Polymorphism (Đa hình)
Mặc dù C không phải là hướng đối tượng, các developer vẫn có thể triển khai một số khái niệm trong ứng dụng của họ để cải thiện đáng kể phần mềm. Vì có nhiều cách để tạo các lớp, kế thừa và đa hình trong C, nên nếu những tính năng này được yêu cầu, thì developer sẽ được nhiều lợi thế hơn khi chỉ sử dụng C++. Các ứng dụng có thể được hưởng lợi rất nhiều từ việc sử dụng tính trừu tượng và tính đóng gói. Hãy cùng khám phá những khái niệm này một cách chi tiết hơn.
ĐỊNH NGHĨA8
Abstraction (Trừu tượng) là tiết lộ chức năng (functionality) và các tính năng phần mềm (software feature) trong khi ẩn việc triển khai thông tin chi tiết.
Encapsulation (Đóng gói) là gói data và code liên quan lại với nhau thành một đơn vị duy nhất.
Object (Đối tượng) là bất kỳ thực thể (entity) nào có trạng thái hoặc hành vi đã biết.
Class (Lớp) là một thực thể phần mềm logic gồm một tập hợp các object.
Inheritance (Kế thừa) là khi một class kế thừa các đặc điểm của class khác.
10. Abstraction và Abstract Data Type (ADT)
Một phép trừu tượng (abstraction) sẽ ẩn chi tiết triển khai (implementation details) lớp dưới trong khi vẫn hiển thị chức năng cần thiết cho developer. Ví dụ: một GPIO driver được triển khai (implement) tốt sẽ cung cấp một giao diện (interface) giúp developer dễ biết những gì có thể được làm với driver, nhưng developer không cần phải biết bất kỳ chi tiết nào về cách driver được triển khai hoặc thậm chí trên phần cứng nào mà driver đó chạy. Abstraction ẩn những chi tiết khỏi developer, tạo ra một hộp đen giúp đơn giản hóa những gì họ cần biết khi sử dụng phần mềm.
Abstraction không chỉ áp dụng cho các giao diện thành phần (component interface). Abstraction còn dễ dàng được áp dụng cho các kiểu dữ liệu (data type). Kiểu dữ liệu trừu tượng (abstract data type), thường được viết tắt là ADT, là kiểu dữ liệu mà chi tiết triển khai của nó bị ẩn khỏi góc nhìn của người dùng (user) bằng một cấu trúc dữ liệu. Có một số phương pháp được sử dụng để tạo ADT trong C. Một phương pháp dễ hiểu có thể được thực hiện trong năm bước đơn giản. Hãy xem cách chúng ta tạo ADT để quản lý ngăn xếp bộ nhớ (memory stack).
Đầu tiên, developer cần xác định kiểu dữ liệu trừu tượng (ADT). ADT trong C thường được định nghĩa (define) là một con trỏ tới một cấu trúc. ADT được khai báo (declare) trong header file mà không có chi tiết cụ thể nào, để người triển khai (implement) khai báo đầy đủ ADT trong source module. Ví dụ về một ADT sẽ là StackPtr_t, NodePtr_t, hoặc QueuePtr_t, để đặt tên cho một số. Nếu developer muốn define một ADT cho một ngăn xếp (stack), họ sẽ bắt đầu bằng cách define đoạn code như Figure 3-14 ở trong file stack.h. Thông tin chi tiết về các member của StackStruct_t được ẩn hoàn toàn dưới góc nhìn của người dùng. Mọi tương tác với StackPtr_t phải được làm bằng các thao tác được define trước.
typedef struct StackStruct_t *StackPtr_t;
Figure 3-14. Defining an ADT
Bước thứ hai để tạo ADT là define các hoạt động (operation) có thể được thực hiện trên data. Các operation có thể được thực hiện trên ADT phụ thuộc hoàn toàn vào mục đích của ADT. Ví dụ, một ADT cho một stack có thể bao gồm các hoạt động sau:
- initialization (khởi tạo)
- pushing data (đẩy dữ liệu)
- popping data (kéo dữ liệu)
- destroying the stack (hủy ngăn xếp)
- checking to see if the stack is full (kiểm tra xem ngăn xếp đã đầy chưa)
- checking to see if the stack is empty (kiểm tra xem ngăn xếp có trống không)
Đừng quên rằng việc sử dụng ADT hoàn toàn khác với cách developer điều khiển data thông thường. Thông thường, developer sẽ define data và viết code điều khiển trực tiếp data. Với kiểu dữ liệu trừu tượng, các developer tạo một giao diện trong đó data được sửa đổi gián tiếp đằng sau hậu trường, việc implement ADT do người khác thực hiện, và cho phép application developer sử dụng data type một cách đơn giản.
Tiếp theo, đặc tả giao diện ADT cần được hoàn thành. Đặc tả giao diện (interface specification) bao gồm các function prototype cho tất cả các public operation có thể được thực hiện trên ADT. Đặc tả giao diện sẽ nằm trong ADT header file. Xem xét ví dụ về stack, bạn có thể thấy rằng đặc tả giao diện trông giống như đoạn code được trong Figure 3-15.
bool Stack_Init(StackPtr_t Stack); bool Stack_Push(StackPtr_t Stackk, int Item); bool Stack_Pop(StackPtr_t Stack, int* Item);
Figure 3-15. Stack ADT interface
Tiếp theo, developer ADT sẽ tạo triển khai ADT hoặc một template cho việc triển khai mà sẽ được điền vào sau. Việc triển khai ADT có thể thay đổi từ ứng dụng này sang ứng dụng kế. Trên thực tế, việc triển khai ADT có thể thay đổi trong quá trình phát triển dự án và một lợi ích chính khi sử dụng ADT là application sử dụng ADT không cần phải thay đổi. Chi tiết triển khai nằm trong module nguồn và “bị ẩn” với developer application cấp cao hơn. Việc sử dụng ADT cung cấp cho developer một độ linh hoạt cao. Một ví dụ triển khai cho stack ADT có thể được tìm thấy trong Figure 3-16 đến Figure 3-19.
#include "stack.h"
struct StackStruct_t
{
int Position_Current;
int Array[STACK_SIZE];
}
Figure 3-16. ADT implementation data structure
Figure 3-16 cho thấy việc triển khai ADT. Cấu trúc triển khai sử dụng một mảng (Array) với kích thước được định nghĩa trước để lưu trữ giá trị stack và một member khác (Position_Current) để theo dõi vị trí trong stack mà giá trị tiếp theo sẽ được thêm vào (add) hoặc loại bỏ (remove).
bool Stack_Init(StackPtr_t Stack)
{
bool Success = false;
Stack = malloc(sizeof(StackStruct_t));
if(Stack != 0)
{
Stack->Position_Current = 0;
Success = true;
}
return Success;
}
Figure 3-17. Stack method initialization
Việc triển khai của ví dụ thậm chí cũng không cấp phát bộ nhớ cho stack đến khi chạy chương trình. Hàm Stack_Init được dùng để cấp phát bộ nhớ động (dynamically allocate memory) cho ADT. Người dùng không có manh mối gì về việc triển khai hoặc cách nó hoạt động như thế nào, thực sự không cần biết hoặc quan tâm! (Trừ khi nó có thể ảnh hưởng đến hiệu suất thời gian thực). Tất cả những gì code ứng dụng cần làm là tạo một con trỏ sẽ được sử dụng để lưu trữ vị trí cho stack. Con trỏ đó thậm chí không bao giờ được sử dụng trực tiếp bởi developer mà chỉ được sử dụng làm đối tượng dữ liệu (data object) để được thao tác bởi các operation function.
Hàm khởi tạo cho stack trong ví dụ triển khai này đang cung cấp một quá trình triển khai vững chắc. Đầu tiên, nó sẽ kiểm tra giá trị trả về của hàm malloc, giá trị này sẽ trả về 0 nếu không thể cấp phát bộ nhớ. Nếu mọi thứ diễn ra như mong đợi, việc triển khai sẽ khởi tạo member vị trí stack và set giá trị trả về.
bool Stack_Push(StackPtr_t Stack, int Item)
{
bool ErrorState = false;
if(Stack->Position_Current == STACK_SIZE)
{
ErrorState = true;
}
else
{
Stack->Array[Stack->Position_Current] = Item;
Stack->Position_Current++;
}
return ErrorState;
}
Figure 3-18. Stack ADT push method
Bước cuối cùng để tạo ADT là đưa ADT vào kiểm tra. ADT có thể được kiểm tra bằng cách viết một số code ứng dụng. Code ứng dụng khai báo một ADT và sau đó thao tác dữ liệu thông qua đặc tả giao diện. Một ví dụ về khởi tạo và kiểm tra đối với stack ADT được thể hiện trong Figure 3-20. Trong ví dụ này, header file stack.h được include trong ứng dụng. ADT theo quan điểm của ứng dụng người dùng (user application) không hơn gì một con trỏ. Hàm Stack_Init được gọi, sau đó thực hiện thao tác trên dữ liệu stack để cấp phát bộ nhớ và chuẩn bị cho việc sử dụng.
bool Stack_Pop(StackPtr_t Stack, int *Item)
{
bool ErrorState = false;
if(Stack->Position_Current == 0)
{
ErrorState = true;
}
else
{
Stack->Position_Current--;
*Item = Stack->Array[Stack->Position_Current];
}
return ErrorState;
}
Figure 3-19. Stack ADT pop method
static StackPtr_t Stack; ... Stack_Init(Stack); Stack_Push(Stack, 0x14);
Figure 3-20. Using the stack ADT
Cuối cùng, data được đẩy (push) lên stack bằng cách gọi Stack_Push. Lưu ý rằng trong ứng dụng ví dụ, chúng ta không kiểm tra các giá trị trả về. Đây là điều mà developer nên làm nhưng tác giả quyết định không thực hiện ở thời điểm này.
Tạo một ADT chỉ đơn giản như vậy! Sử dụng chúng trong phần mềm của bạn sẽ ẩn những chi tiết triển khai của một cấu trúc dữ liệu, do đó cải thiện khả năng bảo trì, tái sử dụng và khả năng port của phần mềm. Các developer sử dụng ADT thấy rằng họ có thể nhanh chóng thích ứng với các yêu cầu thay đổi và tiết kiệm thời gian bằng cách không phải đào sâu xuống code để tìm kiếm các tham chiếu data khó hiểu.
11. Encapsulation và Data Hiding
Đóng gói (Encapsulation) và ẩn dữ liệu (data hiding) là một khái niệm quan trọng mà các developer phần mềm nhúng nên tuân theo. Ý tưởng của Encapsulation là tất cả data, function và operation liên quan nên được gói lại với nhau thành một đơn vị duy nhất. Ví dụ: tất cả các operation đầu vào và đầu ra đa năng (general purpose input and output) sẽ được gói lại với nhau trong một module GPIO duy nhất. Bất kỳ operation và data nào liên quan đến GPIO đều được đưa vào module đó.
Ý tưởng có thể tiến xa hơn bằng cách cân nhắc tới data hiding. Data hiding là nơi các developer ẩn dữ liệu và cách triển khai (implementation) khỏi người dùng module. Điều quan trọng là người gọi các hàm không cần phải hiểu về implementation mà chỉ cần hiểu cách sử dụng giao diện (interface), input và output của nó.
12. Callback Functions
Hàm callback (callback function) là hàm cần thiết và thường là khái niệm trọng yếu mà developer cần có để tạo các driver và custom library. Một hàm callback là một tham chiếu (reference) tới một đoạn code thực thi, dưới hình thức một đối số (argument) được truyền (pass) cho một đoạn code khác, mà đoạn code này cho phép lớp phần mềm thấp hơn (lower-level software layer) gọi một hàm được định nghĩa trong một lớp cao hơn (higher-level layer). Một callback cho phép driver hoặc library developer chỉ định một hành vi tại lớp thấp hơn (lower layer) nhưng lại có thể hiện thực (implement) ở lớp ứng dụng (application layer).
ĐỊNH NGHĨA
Callback9 là một tham chiếu (reference) tới một đoạn code thực thi, dưới hình thức một đối số (argument) được truyền (pass) cho một đoạn code khác, mà đoạn code này cho phép lớp phần mềm thấp hơn (lower-level software layer) gọi một hàm được định nghĩa trong một lớp cao hơn (higher-level layer).
Một hàm callback đơn giản nhất là một con trỏ hàm (function pointer) được truyền làm tham số (parameter) của một hàm khác. Trong hầu hết trường hợp, một callback sẽ có ba phần:
- Hàm callback (The callback function)
- Đăng ký callback (A callback registration)
- Thực thi callback (Callback execution)
Figure 3-21 mô tả sự hoạt động, tương tác của ba phần này trong một callback thông thường.
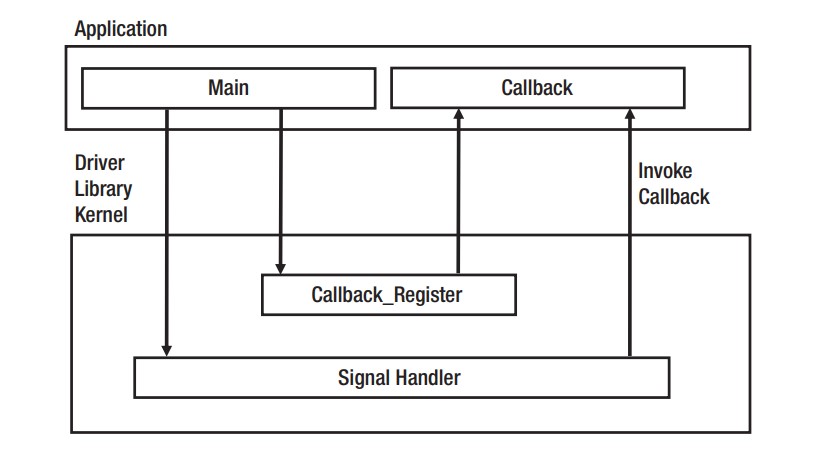
Đầu tiên, developer cần tạo library hoặc module có một phần tử thực hiện (implementation element), phần tử này sẽ được lập trình bởi application developer. Ví dụ như developer tạo một GPIO driver có một interrupt service routine mà phần code của nó được viết bởi application developer. Interrupt này có thể dùng để xử lý (handle) một nút nhấn hoặc một chức năng khác. Driver không cần quan tâm chức năng này, nó chỉ cần biết lúc chạy (runtime) thì hàm nào sẽ được gọi khi interrupt hoạt động. Đoạn code triệu hồi (invoke) hàm callback bên trong module thường được gọi là signal handler.
Tiếp theo, cần có phương tiện để báo cho lower-level code biết hàm nào sẽ được thực thi. Có nhiều cách để làm việc này, nhưng với một driver module, một khuyến cáo là tạo một hàm bên trong module, hàm này được thiết kế đặc biệt để đăng ký (register) một hàm làm một callback. Việc có một hàm tách biệt để đăng ký hàm callback giúp làm rõ với developer rằng hàm callback đang được đăng ký cho một signal handler cụ thể. Khi hàm register được gọi, hàm callback mong muốn sẽ được gọi và được truyền như một parameter vào trong module, và địa chỉ của hàm callback đó được lưu lại.
Cuối cùng, application developer chỉ việc viết application, bao gồm việc tạo phần hiện thực (implemetation) cho callback và code khởi tạo (initialization code) đăng ký hàm đó với library hoặc module. Khi application được thực thi, low-level code đã có địa chỉ được lưu của hàm callback, và khi có chức năng cần thực thi, nó tham chiếu (dereference) tới hàm callback và thực thi hàm callback.
Có hai ví dụ chính mà developer có thể xem xét để sử dụng callback. Thứ nhất, trong các driver, một developer sẽ không biết có bao nhiêu interrupt service routine được dùng ở ứng dụng cuối. Nếu developer đang tạo một library cho vài peripheral của vi điều khiển. Một callback có thể được dùng để chỉ định tất cả hành vi của interrupt. Sử dụng callback sẽ cho phép developer chắc chắn rằng mỗi interrupt đã có một default service routine trong trường hợp application developer không đăng ký hàm custom callback. Khi các callback được dùng với các interrupt, developer cần chú ý tuân theo các phương pháp interrupt tốt nhất.
Thứ hai, các callback có thể được sử dụng bất cứ khi nào có một hành vi chung (common behavior) trong một ứng dụng mà có thể có những hành vi triển khai cụ thể (implementation-specific behaviors). Cho ví dụ, việc khởi tạo một mảng (array) là một task rất chung (a very common task) cần được thực hiện bên trong ứng dụng. Chuyện gì sẽ xảy ra nếu, trong vài ứng dụng, một developer muốn khởi tạo các phần tử của mảng đều là 0; nhưng ở ứng dụng khác, người khác lại muốn khởi tạo các phần tử của mảng là số ngẫu nhiên? Trong trường hợp này, họ cần sử dụng một callback để khởi tạo các mảng.
Xem xét Figure 3-22. Hàm ArrayInit lấy một con trỏ tới một mảng, kích thước mảng và nó cũng lấy một con trỏ hảm trả về số nguyên. Biến hàm Function lúc này chưa cần định nghĩa, nó sẽ được định nghĩa bởi application code. Khi ArrayInit được gọi, developer truyền bất kỳ hàm nào vào để khởi tạo giá trị các phần tử mảng. Một vài hàm ví dụ được truyền vào ArrayInit như trong Figure3-23 và 3-24.
void ArrayInit(int* Array, size_t size, int(*Function)(void))
{
for(size_t i = 0; i < size; i++)
{
Array[i] = Function();
}
}
Figure 3-22. Function with callback
int Zeros(void)
{
return 0;
}
Figure 3-23. Initialize elements to 0
int Random(void)
{
return rand();
}
Figure 3-24. Initialize elements to random numbers
Các hàm Zeros hoặc Random được truyền vào ArrayInit tùy vào cách application developer muốn khởi tạo mảng.
(Đọc tiếp Phần 4)
7https://www.techopedia.com/definition/8982/procedural-language
8http://www.javatpoint.com/java-oops-concepts
9https://en.wikipedia.org/wiki/Callback_(computer_programming)