
Cấu trúc (structure) trong C có thể đại diện cho các phần tử cấu trúc dữ liệu (data structure element), chẳng hạn như các node của một danh sách liên kết (linked list) hoặc cây (tree). Con trỏ (pointer) cung cấp keo gắn kết các yếu tố này lại với nhau. Hiểu được tính linh hoạt của con trỏ cho các cấu trúc dữ liệu phổ biến giúp bạn có khả năng tạo cấu trúc dữ liệu của riêng bạn dễ dàng. Trong bài viết này, chúng ta sẽ tìm hiểu các nguyên tắc cơ bản về cấp phát bộ nhớ cấu trúc trong C (the fundamentals of structure memory allocation in C) và cách implement một số cấu trúc dữ liệu phổ biến.
Cấu trúc nâng ứng dụng của các tập hợp (collection) lên, chẳng hạn như mảng (array). Để tạo một mảng các thực thể, ví dụ như một kiểu màu (color type) với nhiều trường (field) mà không cần sử dụng cấu trúc, ta cần phải khai báo (declare) một mảng cho từng trường và giữ từng giá trị cho một trường trong cùng một chỉ số (index) của từng mảng. Tuy nhiên, với một cấu trúc, chúng ta có thể khai báo một mảng trong đó mỗi phần tử là một thể hiện của cấu trúc (instance of the structure).
Chương này mở rộng các khái niệm con trỏ đã học cho đến nay. Nó bao gồm phần giới thiệu ký hiệu con trỏ khi được sử dụng với cấu trúc, thảo luận về cách bộ nhớ được cấp phát (allocate) cho cấu trúc như thế nào, một kỹ thuật quản lý bộ nhớ được sử dụng bởi cấu trúc và cách sử dụng con trỏ hàm (function pointer).
Chúng ta sẽ bắt đầu với một chủ đề thảo luận về cách bộ nhớ được cấp phát cho một cấu trúc như thế nào. Sự hiểu biết về cấp phát này sẽ giải thích cách hoạt động của những phép toán (operation) khác nhau. Tiếp theo là giới thiệu một kỹ thuật để tối thiểu chi phí quản lý heap.
Phần cuối cùng minh họa cách tạo một số cấu trúc dữ liệu bằng cách sử dụng con trỏ. Danh sách liên kết (linked list) được thảo luận trước và sẽ là nền tảng cho một số cấu trúc dữ liệu khác. Cấu trúc dữ liệu cây (tree) được thảo luận sau cùng và không sử dụng danh sách liên kết.
Introduction
Cấu trúc (structure) có thể được khai báo (declare) theo vài cách. Trong phần này chúng ta chỉ tìm hiểu hai cách tiếp cận, bởi vì mục tiêu của chúng ta là sử dụng nó với con trỏ (pointer). Cách thứ nhất, khai báo structure bằng từ khóa struct. Cách thứ hai, sử dụng định nghĩa kiểu (type definition). Theo khai báo dưới đây, tên của structure có phần tiền tố là một dấu gạch dưới (underscore). Điều này không quan trọng nhưng nó thường được dùng làm quy ước đặt tên. Structure _person bao gồm các trường (field) như name, title, và age:
struct _person {
char* firstName;
char* lastName;
char* title;
unsigned int age;
};
Một khai báo structure thường dùng kèm từ khóa typedef để đơn giản hóa khi sử dụng nó trong chương trình sau này. Dưới đây là mô tả cách viết với cấu trúc _person:
typedef struct _person {
char* firstName;
char* lastName;
char* title;
unsigned int age;
} Person;
Instance của một person được khai báo như sau:
Person person;
Bằng cách này, chúng ta có thể khai báo một con trỏ tới một Person và cấp bộ nhớ cho nó, như dưới đây:
Person *ptrPerson;
ptrPerson = (Person*) malloc(sizeof(Person));
Nếu chúng ta dùng một khai báo structure đơn giản vừa tạo là person, sử dụng dấu chấm (.), dot operator, để truy cập tới các field của nó. Ở ví dụ này, chúng ta sẽ gán giá trị cho hai field firstName và age:
Person person;
person.firstName = (char*)malloc(strlen("Emily")+1);
strcpy(person.firstName,"Emily");
person.age = 23;
Tuy nhiên, nếu chúng ta định dùng một con trỏ tới structure, chúng ta cần sử dụng phép toán trỏ tới (points-to operator), như ví dụ sau. Phép toán này bao gồm một dấu gạch nối và theo sao là dấu lớn ( -> ):
Person *ptrPerson;
ptrPerson = (Person*)malloc(sizeof(Person));
ptrPerson->firstName = (char*)malloc(strlen("Emily")+1);
strcpy(ptrPerson->firstName,"Emily");
ptrPerson->age = 23;
Chúng ta không nhất thiết phải dùng phép toán points-to. Thay vào đó, có thể tham chiếu (dereference) con trỏ rồi áp dụng phép toán chấm (dot operator). Ví dụ dưới đây mô tả cách làm này.
Person *ptrPerson;
ptrPerson = (Person*)malloc(sizeof(Person));
(*ptrPerson).firstName = (char*)malloc(strlen("Emily")+1);
strcpy((*ptrPerson).firstName,"Emily");
(*ptrPerson).age = 23;
Cách viết code này trông có vẻ ngớ ngẩn, nhưng nó lại hoạt động tốt.
How Memory Is Allocated for a Structure
Khi một cấu trúc (structure) được cấp phát bộ nhớ (be allocated memory), số lượng được cấp cho structure là tổng kích thước nhỏ nhất của mỗi trường (field). Tuy nhiên, kích thước (size) thường lớn hơn tổng này, là vì phần đệm (padding) có thể xuất hiện giữa những field của một structure. Sự padding này có từ nhu cầu xếp hàng (align) các kiểu dữ liệu (data type) đúng theo các biên giới (boundary) cụ thể. Ví dụ, một dữ liệu kiểu short thường được xếp hàng trên một vùng địa chỉ chia hết cho hai trong khi một dữ liệu kiểu integer được xếp hàng trên một vùng địa chỉ chia hết cho bốn.
Một số thao tác liên quan đến việc cấp phát bộ nhớ mở rộng (extra memory) này:
- Số học con trỏ (pointer arithmetic) phải được sử dụng cẩn thận
- Mảng cấu trúc (arrays of structures) có thể có bộ nhớ mở rộng giữa các phần tử của nó
Ví dụ, khi một thể hiện (instance) của cấu trúc Person, đã được trình bày trong phần trước, được cấp phát bộ nhớ, nó sẽ được cấp phát 16 byte – 4 byte cho mỗi phần tử. Phiên bản sửa lại của Person sử dụng một short thay vì một unsigned integer cho trường age. Tuy nhiên bộ nhớ được cấp phát vẫn bằng như cũ. Nguyên nhân là do hai byte được đệm ở cuối cấu trúc:
typedef struct _alternatePerson {
char* firstName;
char* lastName;
char* title;
short age;
} AlternatePerson;
Trong trình ví dụ sau, chúng ta khai báo instance cho cả hai cấu trúc Person và AlternatePerson. Kích thước của hai cấu trúc sau đó được hiển thị. Và kích thước của chúng sẽ bằng nhau, 16 byte:
Person person;
AlternatePerson otherPerson;
printf("%d\n",sizeof(Person)); // Displays 16
printf("%d\n",sizeof(AlternatePerson)); // Displays 16
Nếu chúng ta tạo một mảng AlternatePerson, như được thấy bên dưới, sẽ có khoảng đệm giữa các phần tử của mảng. Điều này được minh họa trong Figure 6-1. Vùng tô đậm hiển thị khoảng trống giữa các phần tử mảng.
AlternatePerson people[30];
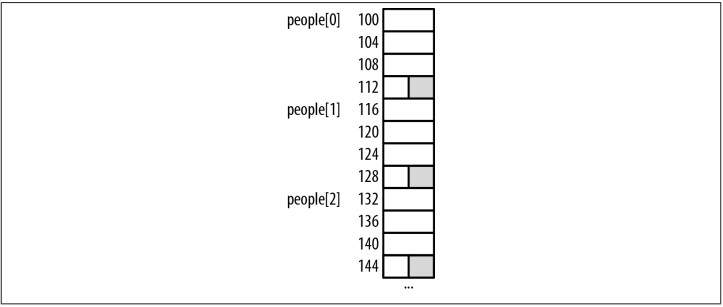
Nếu như chúng ta di chuyển trường age giữa hai trường của cấu trúc, thì phần đệm sẽ nằm bên trong cấu trúc. Tùy thuộc vào cách cấu trúc được truy cập, điều này có thể trở nên đáng lo ngại.
Structure Deallocation Issues
Khi bộ nhớ (memory) được cấp phát (allocate) cho một structure, hệ thống chạy thời gian (runtime system) sẽ không tự động cấp phát bộ nhớ cho bất kỳ con trỏ (pointer) nào bên trong nó. Tương tự, khi structure biến mất, runtime system sẽ không tự động giải phóng (deallocate) bộ nhớ đã được gán cho các con trỏ của structure.
Hãy xem structure dưới đây:
typedef struct _person {
char* firstName;
char* lastName;
char* title;
uint age;
} Person;
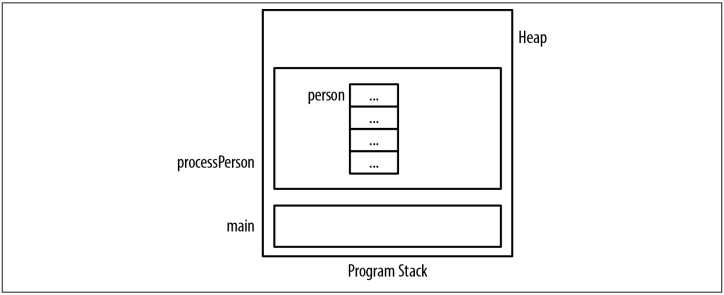
Khi chúng ta khai báo (declare) một biến thuộc kiểu (type) này hoặc cấp phát bộ nhớ động cho kiểu này, 3 con trỏ sẽ chứa thông tin rác. Ở dòng tiếp theo, chúng ta sẽ khai báo một Person. Việc cấp phát bộ nhớ của nó được mô tả trong hình Figure 6-2. Dấu ba chấm chỉ rằng địa chỉ chưa được khởi tạo.
void processPerson() {
Person person;
...
}
Trong khi khởi tạo struture này, mỗi trường (field) sẽ được gán một giá trị. Trường con trỏ sẽ được cấp phát từ heap và được gán cho mỗi con trỏ:
void initializePerson(Person *person, const char* fn,
const char* ln, const char* title, uint age) {
person->firstName = (char*) malloc(strlen(fn) + 1);
strcpy(person->firstName, fn);
person->lastName = (char*) malloc(strlen(ln) + 1);
strcpy(person->lastName, ln);
person->title = (char*) malloc(strlen(title) + 1);
strcpy(person->title, title);
person->age = age;
}
Chúng ta có thể sử dụng hàm này như sau. Figure 6-3 sẽ mô tả bộ nhớ được cấp phát như thế nào:
void processPerson() {
Person person;
initializePerson(&person, "Peter", "Underwood", "Manager", 36);
...
}
int main() {
processPerson();
...
}
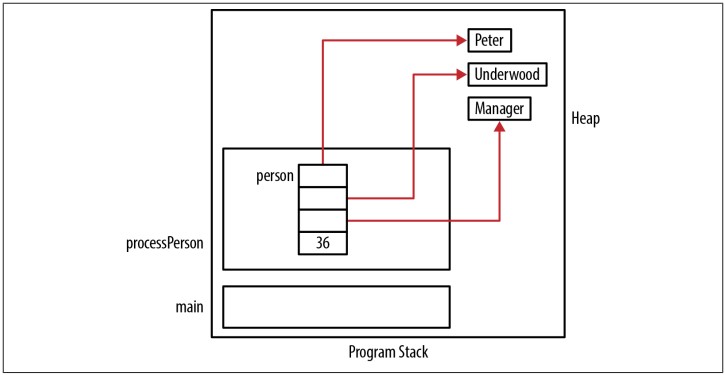
Do khai báo này là một phần của hàm, khi hàm trả về, bộ nhớ cho person sẽ biến mất. Tuy nhiên, chuỗi (string) được cấp phát động không bị mất mà vẫn còn lưu lại trong heap. Không may, chúng ta mất địa chỉ của chúng và chúng ta không thể giải phóng (free) chúng, dẫn đến rò rỉ bộ nhớ (memory leak).
Sau khi sử dụng xong instance, chúng ta cần deallocate bộ nhớ. Hàm tiếp theo sẽ free bộ nhớ đã được allocate khi chúng ta tạo instance:
void deallocatePerson(Person *person) {
free(person->firstName);
free(person->lastName);
free(person->title);
}
Hàm này phải được gọi trước khi hàm processPerson kết thúc:
void processPerson() {
Person person;
initializePerson(&person, "Peter", "Underwood", "Manager", 36);
...
deallocatePerson(&person);
}
Thật không may là chúng ta phải tự nhớ chuyện gọi hàm initialize và deallocate. Việc gọi các thao tác này đối với các object được thực hiện ở các ngôn ngữ hướng đối tượng như là C++.
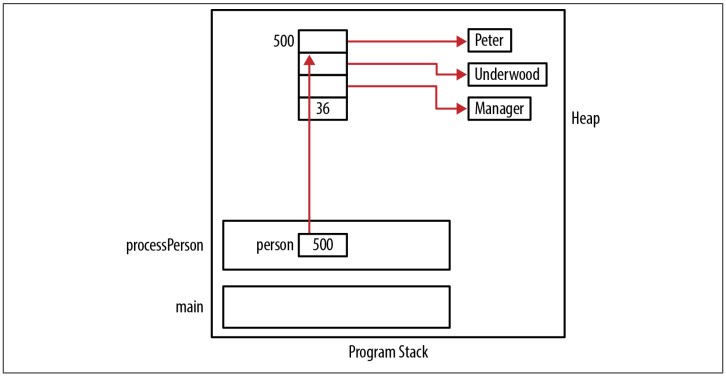
Nếu chúng ta sử dụng một con trỏ Person, chúng ta cần phải nhớ giải phóng các nó như sau:
void processPerson() {
Person *ptrPerson;
ptrPerson = (Person*) malloc(sizeof(Person));
initializePerson(ptrPerson, "Peter", "Underwood", "Manager", 36);
...
deallocatePerson(ptrPerson);
free(ptrPerson);
}
Figure 6-4 mô tả bộ nhớ được allocate ra sao.
Avoiding malloc/free Overhead
Khi các cấu trúc được cấp phát (allocate) rồi được giải phóng (deallocate) lặp đi lặp lại, một số vấn đề sẽ phát sinh, có thể dẫn đến lỗi hiệu suất. Một cách tiếp cận để giải quyết vấn đề này là duy trì danh sách các cấu trúc được cấp phát của riêng bạn. Khi người dùng không còn cần một thể hiện (instance) của cấu trúc nữa, nó sẽ được trả về hồ chứa (pool). Khi cần một instance, nó lấy đối tượng (object) từ pool. Nếu phần tử (element) không có sẵn trong pool, một instance mới sẽ được cấp phát động (dynamically allocate). Cách tiếp cận này duy trì một pool các cấu trúc có thể được sử dụng và tái sử dụng khi cần thiết một cách hiệu quả.
Để chứng minh cách tiếp cận này, chúng ta sẽ sử dụng cấu trúc Person Person được giữ trong một mảng (array). Thật ra, một danh sách (list) phức tạp hơn như danh sách liên kết (linked list) cũng có thể được sử dụng, sẽ được trình bày ở phần “Single-Linked List”. Tuy nhiên để cho ví dụ này đơn giản, chúng ta sẽ sử dụng một mảng con trỏ (an array of pointers). Nó được khai báo (declare) như dưới đây:
#define LIST_SIZE 10 Person *list[LIST_SIZE];
Trước khi list được sử dụng, nó phải được khởi tạo. Hàm tiếp theo gán NULL cho mỗi phần tử của mảng:
void initializeList() {
for(int i=0; i<LIST_SIZE; i++) {
list[i] = NULL;
}
}
Hai hàm được dùng để bổ sung (add) và truy tìm (retrieve) person. Đầu tiên là hàm getPerson, như dưới đây. Hàm này truy tìm một person từ trong list nếu có. Các phần tử của mảng được so sánh với NULL. Phần tử đầu tiên khác NULL được trả về, và vị trí của nó trong list sẽ được gán một giá trị NULL. Nếu không có person nào, thì một instance mới của một Person sẽ được tạo và trả về. Điều này tránh được sự quá tải của việc cấp phát bộ nhớ động cho một person mỗi khi cần một cái mới. Chúng ta chỉ cấp phát bộ nhớ nếu nó không có trong pool. Instance được trả về có thể được khởi tạo trước khi nó được return hoặc bằng caller, tùy theo nhu cầu ứng dụng.
Person *getPerson() {
for(int i=0; i<LIST_SIZE; i++) {
if(list[i] != NULL) {
Person *ptr = list[i];
list[i] = NULL;
return ptr;
}
}
Person *person = (Person*)malloc(sizeof(Person));
return person;
}
Hàm thứ hai là returnPerson, có thể thêm (add) person vào list hoặc giải phóng (free) nó. Các phần tử của mảng được kiểm tra xem có giá trị NULL nào không. Nếu có, thì person được thêm vào vị trí đó và con trỏ (pointer) được trả về. Nếu list đầy (full), thì các con trỏ bên trong person được giải phóng bằng hàm deallocatePerson, person được giải phóng, và sau đó NULL được trả về.
Person *returnPerson(Person *person) {
for(int i=0; i<LIST_SIZE; i++) {
if(list[i] == NULL) {
list[i] = person;
return person;
}
}
deallocatePerson(person);
free(person);
return NULL;
}
Tiếp theo chúng ta sẽ mô tả sự khởi tạo của list và bổ sung person vào list:
initializeList();
Person *ptrPerson;
ptrPerson = getPerson();
initializePerson(ptrPerson,"Ralph","Fitsgerald","Mr.",35);
displayPerson(*ptrPerson);
returnPerson(ptrPerson);
Một vấn đề khi đi theo cách tiếp cận này là kích thước (size) của list. Nếu list quá nhỏ, thì sẽ cần tới nhiều cấp phát và giải phóng bộ nhớ động. Nếu list quá lớn và các structure đang không được dùng, thì một lượng lớn bộ nhớ có thể bị chiếm và không có sẵn cho những việc khác. Do đó một cơ chế quản lý danh sách (list management) phức tạp hơn sẽ được dùng để quản lý kích thước của list.
Using Pointers to Support Data Structures
Con trỏ (pointer) có thể tạo ra nhiều sự linh hoạt cho các cấu trúc dữ liệu (data structure) đơn giản và phức tạp. Tính linh hoạt là do sự cấp phát động của bộ nhớ (dynamic allocation of memory) và việc dễ dàng thay đổi các tham chiếu pointer. Bộ nhớ không nhất thiết phải liền kề nhau, như trường hợp của mảng (array). Mà chỉ cần một lượng bộ nhớ chính xác được cấp phát.
Trong phần này, chúng ta sẽ tìm hiểu cách một vài dạng cấu trúc dữ liệu thường được triển khai (implement) bằng cách sử dụng pointer. Nhiều thư viện C có hỗ trợ sẵn những hàm tương đương và mở rộng hơn những hàm được minh họa ở đây. Tuy nhiên, hiểu cách chúng được implement để có thể chứng tỏ tính hữu ích khi implement các cấu trúc dữ liệu không chuẩn (nonstandard data structure). Trên một số nền tảng (platform), các thư viện có thể không có sẵn và developer sẽ cần phải implement phiên bản của riêng họ.
Chúng ta sẽ xem xét bốn data structure sau:
- Linked list (Danh sách liên kết): Một danh sách liên kết đơn giản
- Queue (Hàng đợi): Một hàng đợi first-in first-out đơn giản
- Stack (Ngăn xếp): Một stack đơn giản
- Tree (Cây): Một cây nhị phân
Cùng với những data structure này, chúng ta sẽ kết hợp với con trỏ hàm (function pointer) để minh họa sức mạnh của pointer khi đương đầu với structure nói chung. Linked List là một data structure rất hữu dụng, và chúng ta sẽ dùng nó làm nền tảng để implement Queue và Stack.
Chúng ta sẽ dùng cấu trúc employee để minh họa các data structure này. Lấy ví dụ, ta có một linked list bao gồm các node liên kết với nhau. Mỗi node sẽ có data do người dùng cung cấp. Một cấu trúc employee đơn giản sẽ như dưới đây. Kiểu dữ liệu (data type) unsigned char dùng cho age là đủ rộng để lưu tuổi con người:
typedef struct _employee {
char name[32];
unsigned char age;
} Employee;
Array được dùng cho một name đơn giản. Mặc dù một pointer tới char là kiểu dữ liệu linh hoạt hơn, tuy nhiên, ở đây chúng ta chọn char array cho trường (field) này để đơn giản hóa ví dụ.
Develop thêm hai function sau. Function thứ nhất so sánh 2 employee và trả về một số nguyên (integer). Function này dựa trên strcmp function. Giá trị 0 được trả về nghĩa là hai cấu trúc employee bằng nhau. Giá trị -1 được trả về nghĩa là employee thứ nhất đứng trước (precede) employee thứ hai theo thứ tự bảng chữ cái alphabet. Giá trị 1 được trả về nghĩa là employee thứ nhất đứng sau (follow) employee thứ hai. Function thứ hai hiển thị một employee:
int compareEmployee(Employee *e1, Employee *e2) {
return strcmp(e1->name, e2->name);
}
void displayEmployee(Employee* employee) {
printf("%s\t%d\n", employee->name, employee->age);
}
Ngoài ra, còn có hai function pointer sẽ được dùng như sau. DISPLAY function pointer chỉ định một function truyền vào một void pointer và trả về void. Công dụng của nó là hiển thị data. Function pointer thứ hai, COMPARE, tượng trưng cho một function được dùng để so sánh hai data được tham chiếu bởi hai pointer. Function này phải so sánh data và trả về 0, hoặc -1, hoặc 1, tương tự như đã giải thích với compareEmployee function:
typedef void(*DISPLAY)(void*); typedef int(*COMPARE)(void*, void*);
Single-Linked List
Danh sách liên kết đơn (linked list) là một cấu trúc dữ liệu (data structure) bao gồm một loạt các node được kết nối với nhau bằng các liên kết (link). Thông thường, một node được gọi là node đầu (head) và các node tiếp theo nối tiếp nhau. Node cuối cùng được gọi là đuôi (tail). Các link nối các node được implement dễ dàng bằng cách sử dụng một pointer. Mỗi node có thể được cấp phát động khi cần tới.
Cách tiếp cận thường được nghĩ tới đầu tiên là một mảng các node. Sử dụng một mảng (array) dẫn đến việc tạo ra một lượng node cố định bất kể việc cần bao nhiêu node. Các link được implement bằng cách sử dụng index của các phần tử (element) của mảng. Cách sử dụng array không linh hoạt bằng cách sử dụng cấp phát bộ nhớ động (dynamic memory allocation) và pointer.
Ví dụ, nếu chúng ta muốn thay đổi thứ tự các phần tử của mảng, thì cần phải sao chép cả hai phần tử và điều đó có thể lớn đối với một cấu trúc. Ngoài ra, việc thêm (add) hoặc xóa (remove) một phần tử có thể yêu cầu di chuyển các phần lớn của mảng để nhường chỗ cho phần tử mới hoặc xóa một phần tử hiện có.
Có một số loại danh sách liên kết. Đơn giản nhất là danh sách liên kết đơn (single-linked list) trong đó có một link duy nhất từ node này đến node tiếp theo. Các link bắt đầu ở phần đầu (head) và cuối cùng dẫn đến phần đuôi (tail). Danh sách liên kết vòng tròn (circular-linked list) không có đuôi. Node cuối cùng của danh sách liên kết trỏ trở lại phần đầu. Danh sách liên kết đôi (doubly linked list) sử dụng hai link, một link trỏ về phía trước và một về phía sau để bạn có thể điều hướng qua danh sách theo cả hai hướng. Loại danh sách liên kết này linh hoạt hơn nhưng khó thực hiện hơn. Figure 6-5 minh họa các loại danh sách liên kết vừa nêu.
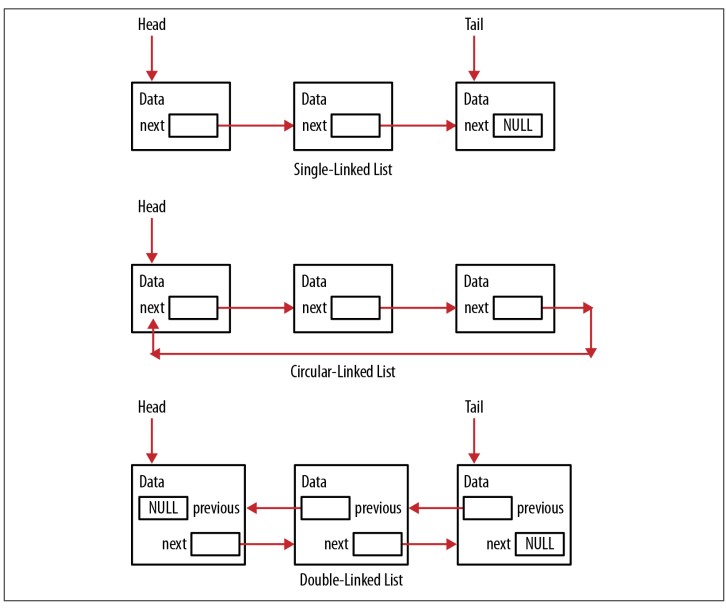
Trong phần này, chúng ta sẽ minh họa việc xây dựng và sử dụng danh sách liên kết đơn. Sau đây là cấu trúc được sử dụng để hỗ trợ danh sách liên kết. Cấu trúc Node được định nghĩa để đại diện cho một node. Nó bao gồm hai pointer. Đầu tiên là một con trỏ void, chứa một kiểu dữ liệu tùy ý. Thứ hai là một pointer đến node tiếp theo, next. Cấu trúc LinkedList đại diện cho danh sách liên kết và giữ một pointer đến phần đầu (head) và phần đuôi (tail). Pointer hiện tại sẽ giúp duyệt qua danh sách liên kết:
typedef struct _node {
void *data;
struct _node *next;
} Node;
typedef struct _linkedLidt {
Node *head;
Node *tail;
Node *current;
} LinkedList;
Chúng ta sẽ develop vài hàm sử dụng những cấu trúc này để hỗ trợ chức năng của danh sách liên kết.
void initializeList(LinkedList*) // Initializes the linked list void addHead(LinkedList*, void*) // Adds data to the linked list’s head void addTail(LinkedList*, void*) // Adds data to the linked list’s tail void delete(LinkedList*, Node*) // Removes a node from the linked list Node *getNode(LinkedList*, COMPARE, void*) // Returns a pointer to the node containing a specific data item void displayLinkedList(LinkedList*, DISPLAY) // Displays the linked list
Để có thể sử dụng linked list thì nó cần phải được khởi tạo (initialize). Hàm initializeList, như trên, thực hiện nhiệm vụ này. Một con trỏ tới object LinkedList được pass vào hàm để làm việc set các con trỏ thành NULL:
void initializeList(LinkedList *list) {
list->head = NULL;
list->tail = NULL;
list->current = NULL;
}
Hàm addHead và addTail lần lượt add data vào head và tail của linked list. Ở cách implement linked list này, hàm add và delete đảm nhận vai trò cấp phát (allocate) và giải phóng (free) bộ nhớ được dùng cho các node của linked list.
Trong hàm addHead dưới đây, bộ nhớ trước tiên được cấp cho node và data được pass vào hàm sẽ được gán cho trường (field) data của cấu trúc. Tiếp theo, chúng ta kiểm tra xem linked list có bị empty không. Nếu có, chúng ta gán tail pointer trỏ tới node và gán NULL vào next field của node. Nếu không, next pointer của node được gán tới head của list. Cuối cùng, gán head của list với node:
void addHead(LinkedList *list, void* data) {
Node *node = (Node*) malloc(sizeof(Node));
node->data = data;
if (list->head == NULL) {
list->tail = node;
node->next = NULL;
} else {
node->next = list->head;
}
list->head = node;
}
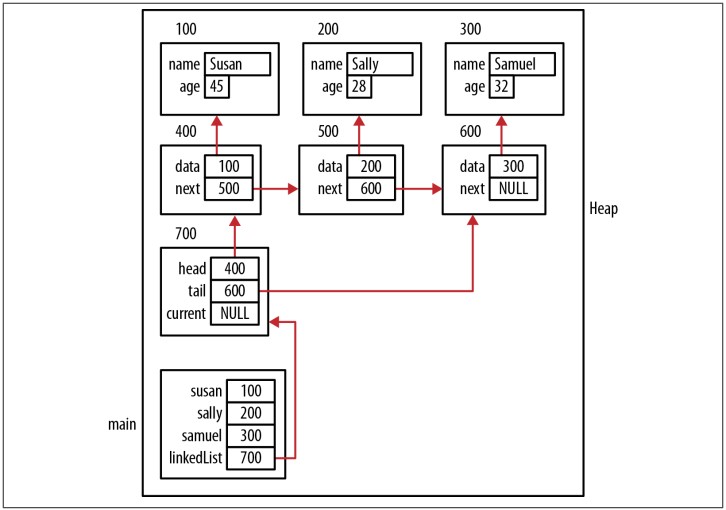
Đoạn code tiếp theo mô tả cách dùng hàm initializeList và addHead. Ba employee được thêm vào list. Figure 6-6 cho thấy bộ nhớ được cấp phát như thế nào sau khi những dòng lệnh này thực thi. Nhiều mũi tên đã bị lược bỏ để đơn giản hóa sơ đồ. Ngoài ra, mảng name trong cấu trúc Employee đã bị đơn giản hóa.
LinkedList linkedList;
Employee *samuel = (Employee*)malloc(sizeof(Employee));
strcpy(samuel->name, "Samuel");
samuel->age = 32;
Employee *sally = (Employee*)malloc(sizeof(Employee));
strcpy(sally->name, "Sally");
sally->age = 28;
Employee *susan = (Employee*)malloc(sizeof(Employee));
strcpy(susan->name, "Susan");
susan->age = 45;
initializeList(&linkedList);
addHead(&linkedList, samuel);
addHead(&linkedList, sally);
addHead(&linkedList, susan);
Hàm addTail như dưới đây. Đầu tiên, nó cấp phát bộ nhớ cho một node mới và gấn data vào data field. Vì node luôn luôn được add vào tail, next field của node được gán là NULL. Nếu linked list là empty, thì head pointer cũng là NULL, và head có thể được gán tới node mới. Nếu không NULL, thì next pointer của tail được gán tới node mới. Cuối cùng tail pointer của linked list được update/gán tới node:
void addTail(LinkedList *list, void* data) {
Node *node = (Node*) malloc(sizeof(Node));
node->data = data;
node->next = NULL;
if (list->head == NULL) {
list->head = node;
} else {
list->tail->next = node;
}
list->tail = node;
}
Đoạn code dưới đây mô tả cách sử dụng hàm addTail. Việc tạo những object employee đã không bị trùng lặp (duplicate) ở đây. Những employee đã được add theo thứ tự ngược lại so với ví dụ trước bằng hàm addTail. Do đó kết quả cấp phát bộ nhớ sẽ giống như Figure 6-6:
initializeList(&linkedList);
addTail(&linkedList, susan);
addTail(&linkedList, sally);
addTail(&linkedList, samuel);
Hàm delete sẽ remove một node trong linked list. Để đơn giản hóa hàm này, một pointer trỏ tới node cần xóa sẽ được pass vào nó. Có lẽ người sử dụng hàm có một pointer trỏ tới data nhưng lại không có pointer trỏ tới node nắm giữ data này. Để xác định node, một hàm hỗ trợ được cung cấp để trả về một pointer trỏ tới node: getNode. Hàm getNode cần truyền vào 3 tham số (parameter):
- Một pointer trỏ tới linked list
- Một pointer trỏ tới hàm so sánh (comparision function)
- Một pointer trỏ tới dữ liệu (data) cần tìm
Code của hàm getNode như sau. Biến node được khởi tạo trỏ vào head của list và di chuyển dọc list đến khi tìm được giá trị tương đồng (match) hoặc gặp điểm cuối của linked list. Hàm compare được gọi để xác định giá trị có giống nhau không. Khi hai data bằng nhau, nó trả về zero.
Node *getNode(LinkedList *list, COMPARE compare , void* data) {
Node *node = list->head;
while (node != NULL) {
if (compare(node->data, data) == 0) {
return node;
}
node = node->next;
}
return NULL;
}
Hàm compare sử dụng một con trỏ hàm (function pointer) lúc chạy để kiểm tra xem hàm nào dùng để so sánh. Cách làm này tăng tính linh hoạt đáng kể cho việc implement linked list, bởi vì chúng ta không cần phải code cứng (hard code) tên hàm trong hàm getNode.
Tiếp theo là hàm delete. Để giữ cho hàm đơn giản, người ta không kiểm tra giá trị null của linked list và node được truyền vào hàm. Điều kiện if đầu tiên dùng để xóa một node ở head. Nếu node ở head là node duy nhất, thì head và tail đều được gán giá trị null. Ngược lại head bị gán cho node tiếp theo của head.
Điều kiện else sử dụng một con trỏ tmp đi xuyên qua (traverse) list từ head đến tail. Vòng lặp while sẽ bị ngắt nếu tmp là NULL, nghĩa là node đó không tồn tại trong list, hoặc node tiếp sau tmp là node mà ta đang tìm. Vì đây là single-linked list, chúng ta cần biết node nào đứng trước node sắp bị xóa, khi đó node tiếp theo của node sắp bị xóa sẽ được gán vào trường next của node đứng trước nó (node bị xóa). Người dùng có trách nhiệm xóa data của node trước khi hàm delete được gọi.
void delete(LinkedList *list, Node *node) {
if(node == list->head)
{
if(list->head->next == NULL) {
list->head = list->tail = NULL;
} else {
list->head = list->head->next;
}
} else {
Node *tmp = list->head;
while(tmp != NULL && tmp->next != node) {
tmp = tmp->next;
}
if(temp != NULL)
{
temp->next = node->next;
}
}
free(node);
}
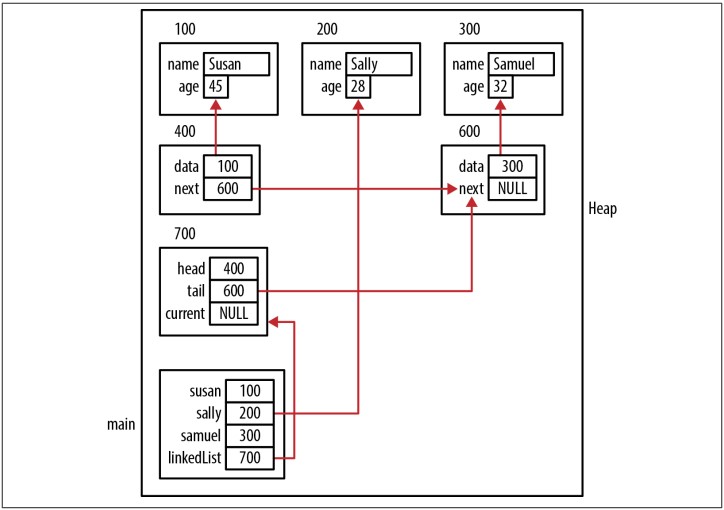
Sử dụng hàm delete theo cách sau. Ba employee lần lượt được thêm vào head của linked list. Chúng ta sẽ dùng hàm compareEmployee trong phần “Using Pointers to Support Data Structures” để so sánh:
addHead(&linkedList, samuel);
addHead(&linkedList, sally);
addHead(&linkedList, susan);
Node *node = getNode(&linkedList,
(int (*)(void*, void*))compareEmployee, sally);
delete(&linkedList, node);
Khi chuỗi code này thực thi, stack và heap chương trình sẽ như Figure 6-7.
Hàm displayLinkedList dùng để print tất cả node của linked list. Nó bắt đầu tại head và in mỗi phần tử bằng hàm được truyền vào tham số (argument) thứ hai. Node pointer được gán với trường next và sẽ kết thúc khi node cuối cùng được hiển thị.
void displayLinkedList(LinkedList *list, DISPLAY display) {
printf("\nLinked List\n");
Node *current = list->head;
while (current != NULL) {
display(current->data);
current = current->next;
}
}
Ví dụ sau sử dụng hàm displayEmployee đã được develop ở phần “Using Pointers to Support Data Structures”.
addHead(&linkedList, samuel);
addHead(&linkedList, sally);
addHead(&linkedList, susan);
displayLinkedList(&linkedList, (DISPLAY)displayEmployee);
Kết quả in ra sẽ như sau:
Linked List Susan 45 Sally 28 Samuel 32
Using Pointers to Support a Queue
Hàng đợi (queue) là cấu trúc dữ liệu tuyến tính (linear data structure) có hành vi giống như một dãy xếp hàng đơi (waiting line). Nó thường hỗ trợ hai phép toán (operation) chủ yếu là: enqueue và dequeue. Phép toán enqueue thêm một phần tử (element) vào queue. Phép toán dequeue lấy ra (remove) một phần tử từ queue. Thông thường, phần tử đầu tiên được thêm vào queue sẽ là phần tử đầu tiên bị dequeue khỏi queue. Hành vi này gọi là First-In-First-Out (FIFO).
Người ta thường lấy linked list để implement một queue. Phép toán euqueue sẽ cộng (add) một node vào head của linked list và phép toán dequeue sẽ lấy ra (remove) một node ở tail. Để mô tả queue, chúng ta sẽ sử dụng lại linked list vừa develop ở phần “Single-Linked List”.
Hãy bắt đầu với phát biểu định nghĩa kiểu (type definition) để định nghĩa một kiểu queue. Nó sẽ dựa trên một linked list như dưới đây. Chúng ta có thể sử dụng Queue để việc thiết kế rõ ràng hơn:
typedef LinkedList Queue;
Để implement hàm khởi tạo, chúng ta chỉ cần dùng lại hàm initializeList. Thay vì gọi trực tiếp hàm này, chúng ta sẽ gọi bằng hàm initializeQueue:
void initializeQueue(Queue *queue) {
initializeList(queue);
}
Tương tự, hàm tiếp theo sẽ add một node vào queue bằng hàm addHead:
void enqueue(Queue *queue, void *node) {
addHead(queue, node);
}
Cách implement linked list ở phần trước không có hàm remove node ở tail một cách tường minh. Hàm dequeue sau đây remove node cuối cùng. Ba điều kiện sau cần được xử lý:
- Một queue rỗng (an empty queue): Trả về
NULL - Một queue đơn node (a single node queue): Xử lý bằng
if else - Một queue nhiều node (a multiple node queue): Xử lý bởi
else
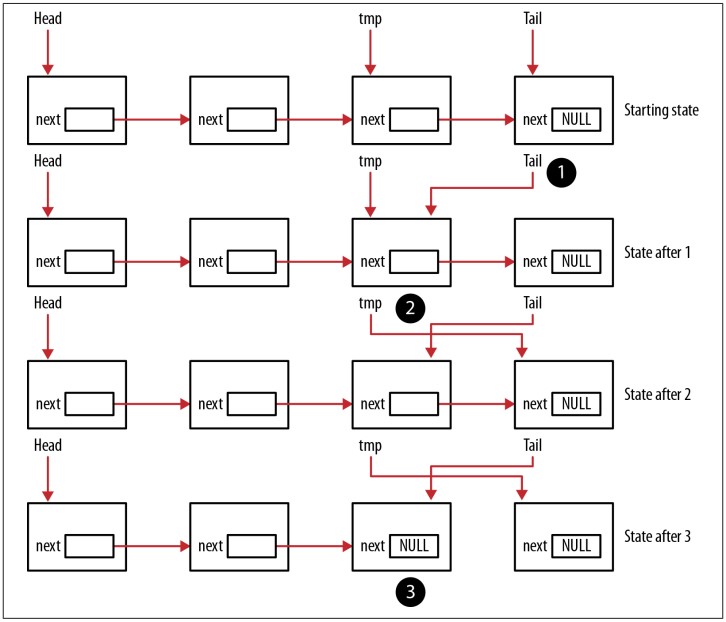
Ở những trường hợp sau nữa, con trỏ tmp được tận dụng
Trong trường hợp sau, con trỏ tmp được nâng cao từng node cho đến khi nó trỏ đến node ngay trước node tail. Ba hoạt động đó được thực hiện theo trình tự sau:
- Node tail được gán cho node
tmp - Con trỏ
tmpđược tăng lên tới node tiếp theo - Trường
nextcủa tail được set làNULLđể chỉ ra rằng không còn node nào nữa trong queue
Trình tự này cần thiết để đảm bảo tính toàn vẹn (integrity) của list, như mô tả khái niệm ở Figure 6-8. Các số khoanh tròn tương ứng với ba bước liệt kê bên trên:
void *dequeue(Queue *queue) {
Node *tmp = queue->head;
void *data;
if (queue->head == NULL) {
data = NULL;
} else if (queue->head == queue->tail) {
queue->head = queue->tail = NULL;
data = tmp->data;
free(tmp);
} else {
while (tmp->next != queue->tail) {
tmp = tmp->next;
}
queue->tail = tmp;
tmp = tmp->next;
queue->tail->next = NULL;
data = tmp->data;
free(tmp);
}
return data;
}
Dữ liệu được gán cho node được trả về, và node được giải phóng (free). Các chức năng này được minh họa trong đoạn code sau, sử dụng lại các employee đã tạo trước đó:
Queue queue;
initializeQueue(&queue);
enqueue(&queue, samuel);
enqueue(&queue, sally);
enqueue(&queue, susan);
void *data = dequeue(&queue);
printf("Dequeued %s\n", ((Employee*)data)->name);
data = dequeue(&queue);
printf("Dequeued %s\n", ((Employee*)data)->name);
data = dequeue(&queue);
printf("Dequeued %s\n", ((Employee*)data)->name);
Kết quả output như sau:
Dequeued Samuel Dequeued Sally Dequeued Susan
Để implement hàm khởi tạo, chúng ta chỉ cần dùng lại hàm initializeList. Thay vì gọi trực tiếp hàm này, chúng ta sẽ gọi bằng hàm initializeQueue:
Using Pointers to Support a Stack
Cấu trúc dữ liệu ngăn xếp (stack data structure) cũng là một kiểu của list. Ở trường hợp này các phần tử (element) được đẩy vào (push) đỉnh (top) của stack và sau đó được lấy ra (pop). Khi nhiều phần tử được push rồi pop, hành vi này tựa như First-In-Last-Out (FILO). Phần tử đầu tiên được push vào stack sẽ là phần tử cuối cùng được pop ra.
Giống như cách implement queue, chúng ta có thể sử dụng linked list để làm những phép toán (operation) của stack. Hai phép toán cơ bản nhất chính là phép toán push và pop. Phép toán push sẽ dùng lại từ hàm addHead. Phép toán pop thì cần bổ sung hàm xóa (remove) node head. Bắt đầu bằng định nghĩa một stack dựa trên linked list như sau:
typedef LinkedList Stack;
Để khởi tạo stack, chúng ta tạo thêm hàm initializeStack. Hàm này gọi hàm initializeList:
void initializeStack(Stack *stack) {
initializeList(stack);
}
Phép toán push gọi hàm addHead như sau:
void push(Stack *stack, void* data) {
addHead(stack, data);
}
Cách implement phép toán pop như sau. Đầu tiên gán head của stack với một node pointer. Nó cần giải phải quyết được 3 điều kiện:
- Stack rỗng (empty): hàm trả về NULL
- Stack chứa một phần tử: nếu node trỏ tới tail, thì head và tail là cùng phần tử. Head và tail được gán giá trị NULL, và data được trả về.
- Stack chứa nhiều hơn một phần tử: trường hợp này, head được gán với phần tử tiếp theo (next element), và data được trả về.
Ở hai trường hợp sau, node được giải phóng (free)
void *pop(Stack *stack) {
Node *node = stack->head;
if (node == NULL) {
return NULL;
} else if (node == stack->tail) {
stack->head = stack->tail = NULL;
void *data = node->data;
free(node);
return data;
} else {
stack->head = stack->head->next;
void *data = node->data;
free(node);
return data;
}
}
Chúng ta sẽ tái sử dụng những ví dụ đã tạo ở phần “Single-Linked List” để mô tả stack. Chuỗi code sau push liên tiếp 3 employee đã tạo rồi pop chúng ra khỏi stack.
Stack stack;
initializeStack(&stack);
push(&stack, samuel);
push(&stack, sally);
push(&stack, susan);
Employee *employee;
for(int i=0; i<4; i++) {
employee = (Employee*) pop(&stack);
printf("Popped %s\n", employee->name);
}
Khi thực thi, chúng ta nhận được kết quả như sau. Vì chúng ta dùng hàm pop 4 lần, NULL được trả về tại lần cuối cùng.
Popped Susan Popped Sally Popped Samuel Popped (null)
Ngoài ra, còn những phép toán stack khác, đôi lúc như phép toán xem trước (peek) trong đó phần tử trên cùng được trả về nhưng không được pop ra khỏi stack.
Using Pointers to Support a Tree
Cây (tree) là một cấu trúc dữ liệu cực kỳ hữu dụng. Tên của nó được suy ra từ mối quan hệ giữa các phần tử. Thông thường, node con (child node) được gắn với node cha mẹ (parent node). Dạng tổng quát là một cây đảo (inverted tree) có vị trị node gốc cây (root node) đại diện cho phần tử bắt đầu của cấu trúc dữ liệu.
Một tree có thể có bao nhiêu child node cũng được. Tuy nhiên, cây nhị phân (binary tree) thường phổ biến hơn, với mỗi node sở hữu các child node không (zero), một, hoặc hai. Các con được thiết kế làm con trái (left child) hoặc con phải (right child). Những node không có con được gọi là node lá (leaf node), giống như những chiếc lá trên một cái cây. Các ví dụ ở phần này sẽ mô tả một binary tree.
Con trỏ (pointer) đem lại một cách rõ ràng và linh hoạt để duy trì mối quan hệ giữa những tree node. Các node được cấp phát động (dynamically allocate) và thêm (add) vào tree mỗi khi cần. Chúng ta sẽ dùng cấu trúc sau cho một node. Sử dụng một void pointer để cho phép chúng ta xử lý bất kỳ loại data nào cần đến:
typedef struct _tree {
void *data;
struct _tree *left;
struct _tree *right;
} TreeNode;
Khi ta add các node vào một tree, nó cần phải được add theo một thứ tự cụ thể. Điều này sẽ làm cho nhiều phép toán (operation), như tìm kiếm (search), dễ hơn. Một thứ tự phổ biến là add một node mới vào tree theo cách là toàn bộ child node sở hữu giá trị nhỏ hơn parent node và toàn bộ child bên phải sở hữu giá trị lớn hơn parent node. Gọi là cây tìm kiếm nhị phân (binary search tree).
Hàm insertNode sau sẽ chèn (insert) một node vào binary search tree. Tuy nhiên, để insert một node, cần có một hàm so sánh (comparison) được thực hiện giữa node mới và node hiện có của tree. Chúng ta sử dụng con trỏ hàm COMPARE để pass địa chỉ của hàm so sánh. Phần đầu của hàm cấp pháp bộ nhớ cho node mới và gán data vào node. Left và right child được set thành NULL vì node mới được add luôn được xem là một leaf của tree:
void insertNode(TreeNode **root, COMPARE compare, void* data) {
TreeNode *node = (TreeNode*) malloc(sizeof(TreeNode));
node->data = data;
node->left = NULL;
node->right = NULL;
if (*root == NULL) {
*root = node;
return;
}
while (1) {
if (compare((*root)->data, data) > 0) {
if ((*root)->left != NULL) {
*root = (*root)->left;
} else {
(*root)->left = node;
break;
}
} else {
if ((*root)->right != NULL) {
*root = (*root)->right;
} else {
(*root)->right = node;
break;
}
}
}
}
Đầu tiên, root được kiểm tra xem có rỗng (empty) không. Nếu có, thì node mới sẽ được gán cho root và hàm trả về. Root được pass như một con trỏ hai lớp trỏ vào TreeNode (a pointer to a pointer to a TreeNode). Điều này là cần thiết bởi vì chúng ta cần thay đổi (modify) con trỏ được pass vào hàm, chứ không phải cái mà con trỏ trỏ tới (what the pointer points to).
Nếu tree không rỗng, thì một vòng lặp vô tận sẽ tới và kiểm tra xem khi nào node mới được add vào tree. Với mỗi lần lặp lại, node mới và parent node hiện tại được so sánh. Ở mức cơ bản của sự so sánh, con trỏ root local sẽ được gán lại (reassign) cho left child hoặc right child. Con trỏ root này trỏ tới node hiện tại của tree. Nếu left hoặc right child là NULL, thì node được add vào làm child và vòng lặp kết thúc.
Để mô tả hàm insertNode, chúng ta sẽ dùng lại những ví dụ employee đã tạo ở phần “Using Pointers to Support Data Structures”. Trình tự sau khởi tạo một TreeNode rỗng rồi insert ba employee. Kết quả trạng thái của stack và heap chương trình sẽ như Figure 6-9. Vài mũi tên chỉ tới employee đã được loại bỏ để đơn giản hóa sơ đồ. Sự bố trí các node trong heap cũng được sắp xếp để phản ánh thứ tự của cấu trúc tree:
TreeNode *tree = NULL;
insertNode(&tree, (COMPARE) compareEmployee, samuel);
insertNode(&tree, (COMPARE) compareEmployee, sally);
insertNode(&tree, (COMPARE) compareEmployee, susan);
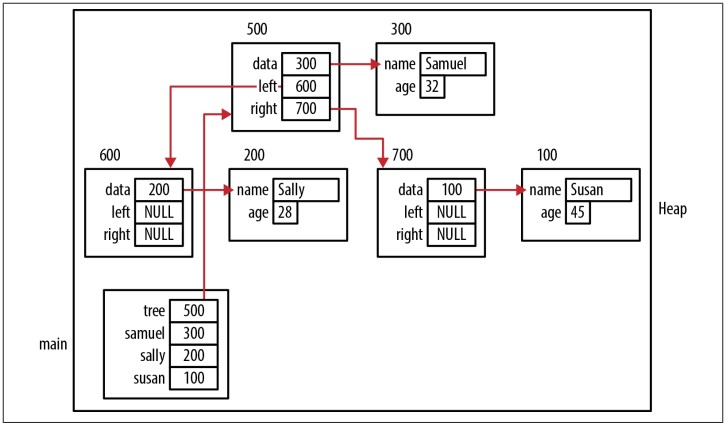
Figure 6-9. insertNode function

Figure 6-10 mô tả cấu trúc logic của tree này.
Binary tree được sử dụng cho nhiều mục đích và có thể được di chuyển (traverse) bằng ba hướng khác nhau: thứ tự trước (pre-order), thứ tự trong (in-order), thứ tự sau (post-order). Ba kỹ thuật này dùng các bước (step) giống nhau, nhưng chúng được thực hiện theo thứ tự (order) khác nhau. Ba bước gồm:
- Thăm node (visit the node): xử lý node
- Đi trái (go left): Di chuyển qua left node
- Đi phải (go right): Di chuyển qua right node
Theo mục đích của chúng ta, thăm node nghĩa là hiển thị (display) nội dung của nó. Ba kiểu thứ tự như sau:
- In-order: Go left, visit the node, go right
- Pre-order: Visit the node, go left, go right
- Post-order: Go left, go right, visit the node
Cách implement của hàm được trình bày dưới đây. Mỗi tham số pass vào gồm một root của tree và một con trỏ hàm cho hàm display. Chúng là đệ quy (recursive) và sẽ gọi chính nó miễn là root node được pass vào không phải là null. Chúng chỉ khác nhau về thứ tự thực hiện ba bước:
void inOrder(TreeNode *root, DISPLAY display) {
if (root != NULL) {
inOrder(root->left, display);
display(root->data);
inOrder(root->right, display);
}
}
void postOrder(TreeNode *root, DISPLAY display) {
if (root != NULL) {
postOrder(root->left, display);
postOrder(root->right, display);
display(root->data);
}
}
void preOrder(TreeNode *root, DISPLAY display) {
if (root != NULL) {
display(root->data);
preOrder(root->left, display);
preOrder(root->right, display);
}
}
Chuỗi code sau đây gọi các hàm:
preOrder(tree, (DISPLAY) displayEmployee);
inOrder(tree, (DISPLAY) displayEmployee);
postOrder(tree, (DISPLAY) displayEmployee);
Table 6-1 cho thấy output của mỗi lệnh gọi hàm dựa trên lần khởi tạo trước đó của tree.
| pre-order | Samuel 32 | Sally 28 | Susan 45 |
| in-order | Sally 28 | Samuel 32 | Susan 45 |
| post-order | Sally 28 | Susan 45 | Samuel 32 |
Việc đi theo in-order sẽ trả về danh sách được sắp xếp các member của tree. Đi theo pre-order và post-order có thể được sử dụng để đánh giá các biểu thức số học khi được sử dụng kết hợp với stack và queue.
Summary
Sức mạnh và tính linh hoạt của con trỏ được chứng minh khi dùng nó để chế tạo và hỗ trợ cấu trúc dữ liệu (data structure). Kết hợp với cấp phát bộ nhớ động (dynamic memory allocation) của cấu trúc, con trỏ khiến cho việc tạo cấu trúc dữ liệu có thể sử dụng bộ nhớ hiệu quả, có thể phát triển và thu nhỏ để đáp ứng nhu cầu của ứng dụng.
Chúng ta đã bắt đầu bài viết này với một chủ đề thảo luận về cách bộ nhớ được cấp phát (allocate) cho các cấu trúc (structure). Padding giữa các trường của cấu trúc (field’s structure) và giữa các mảng cấu trúc (arrays of structure) là khả dĩ. Cấp phát bộ nhớ động và giải phóng bộ nhớ (deallocate) có thể tốn kém. Chúng ta đã kiểm tra một kỹ thuật để duy trì một nhóm các cấu trúc (a pool of structure) để tối thiểu chi phí này.
Chúng ta cũng đã chứng minh cách triển khai (implement) một số cấu trúc dữ liệu thông dụng. Danh sách liên kết (linked list) đã được sử dụng để hỗ trợ một số cấu trúc dữ liệu này. Con trỏ hàm (function pointer) đã được sử dụng để thêm tính linh hoạt cho các implement này bằng cách cho phép chọn hàm so sánh hoặc hàm hiển thị trong thời gian chạy.